fastai07-Sizing and Tta

本章主要是介绍了几种先进技术
Normalization | 归一化
这个在 Andrej Karpathy的视频里讲得更清楚
Neural Networks: Zero to Hero
Share your videos with friends, family, and the world


fastai先是给出了结论
在训练模型时,如果输入数据被归一化(即均值为 0,标准差为 1),训练效果会更好。
然后给了一个例子, 对比了有批量归一化层和没有批量归一化层,其实效果差不多,但是
虽然它在这里只起了一点作用,但在使用预训练模型时,归一化变得尤为重要。预训练模型只知道如何处理它以前见过的类型的数据。如果用于训练的数据中的平均像素值为 0,但您的数据将 0 作为像素的最小可能值,那么模型将看到与预期截然不同的内容!
Progressive Resizing | 渐进式调整大小
基本思想
从小图像开始训练,然后使用大图像结束训练。将大部分时间花在小图像上训练,有助于更快地完成训练。使用大图像完成训练可以使最终精度更高。

Test Time Augmentation | 测试时间增强
基本思想
在推理或验证过程中,使用数据增强创建每个图像的多个版本,然后对每个增强版本的图像的预测结果取平均值或最大值。
preds,targs = learn.tta()
accuracy(preds, targs).item()Mixup | 混合
一张图说明一切
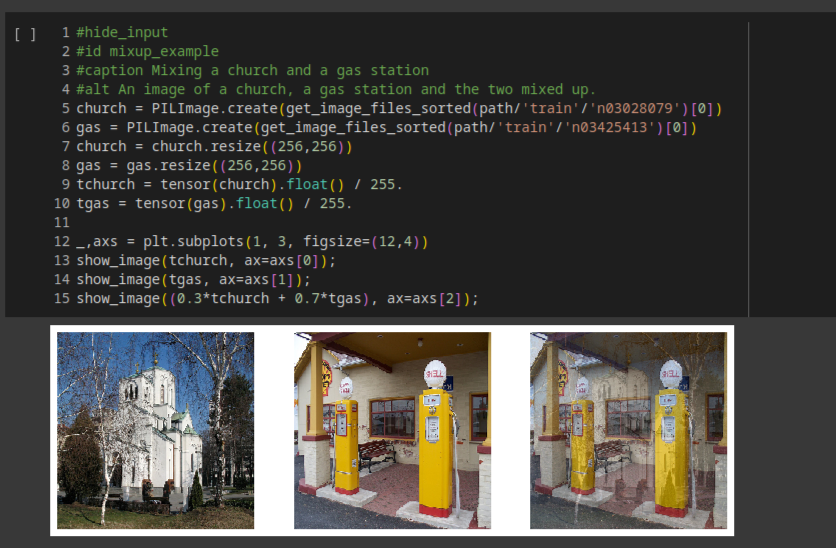
第三张图像是通过加上第一张图像的0.3倍和第二张图像的0.7倍构建的.假设我们有10个类别,"教堂"由索引2表示,"加油站"由索引7表示,那么one-hot编码的表示是:
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0] and [0, 0, 0, 0, 0, 0, 0, 1, 0, 0]因此我们的目标target是
[0, 0, 0.3, 0, 0, 0, 0, 0.7, 0, 0]因为我们在每个周期中展示的不是同一张图片,而是两张图片的随机组合,Mixup可以有效的防止过拟合.另外Mixup帮我们处理了另一个微妙的问题,那就是我们以前看到的模型实际上无法使我们的损失完美.原因在于我们的标签是1和0,但是softmax和sigmoid的输出永远不能等于1或0.这意味着训练我们的模型会使我们的激活值越来越接近这些值,以至于我们做的epoch越多,我们的激活值就会变得越极端.
Label Smoothing | 标签平滑
基本思想
你的数据永远不会完美.我们可以用稍小于1的数替换所有的1,用稍大于0的数替换所有的0,然后进行训练。这就叫做标签平滑。通过鼓励你的模型不要过于自信,标签平滑会使你的训练更加稳健,即使存在标签错误的数据。结果将是一个泛化能力更强的模型。
具体替换规则是这样的.用 ϵ/N 替换所有的0,其中 N 是类别的数量, ϵ 是一个参数(通常为0.1,这意味着我们对我们的标签有10%的不确定性).由于我们希望标签的总和为1,所以将1替换为 1−ϵ+ϵN.
[0.01, 0.01, 0.01, 0.91, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01]