fastai08-collab

协同过滤
协同过滤,它的工作方式是这样的:看看当前用户使用或喜欢的产品,找到使用或喜欢类似产品的其他用户,然后推荐那些用户使用或喜欢的其他产品。
我们假设评价一个电影有三个因素,factor1, factor2, factor3,1代表非常匹配,-1代表非常不匹配,那么movie1用数组这样表示
movie1 = np.array([0.98,0.9,-0.9])用户对这三个factor的匹配度
user1 = np.array([0.9,0.8,-0.6])计算这个组合的匹配度
(user1*movie1).sum()2.1420000000000003
数据是这样的
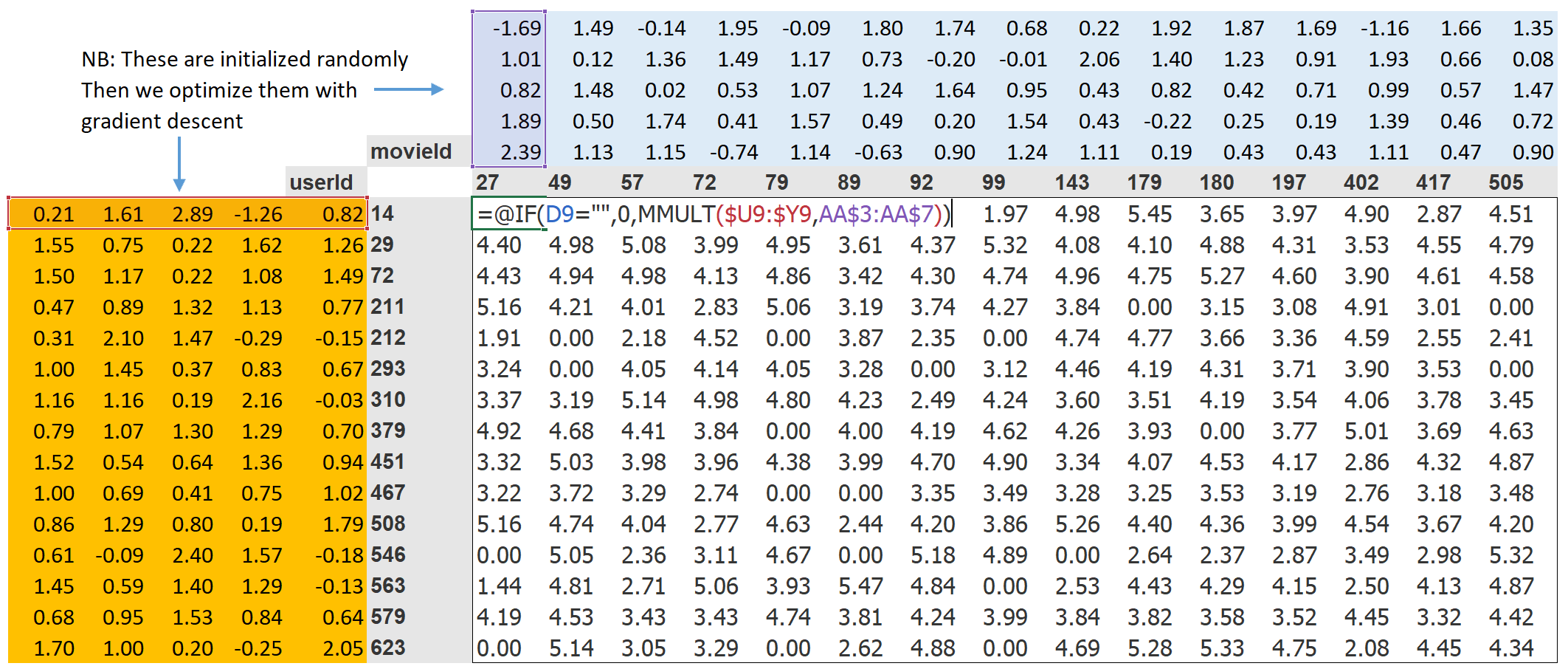
我们将为我们的每个用户和每部电影分配一个特定长度(这里是 n_factors=5 )的随机向量,并将这些作为可学习的参数在开始时,这些数字并没有任何意义,因为我们是随机选择的,但到训练结束时,它们就有了意义.网络结构是这样的
class DotProductBias(Module):
def __init__(self, n_users, n_movies, n_factors, y_range=(0,5.5)):
self.user_factors = Embedding(n_users, n_factors)
self.user_bias = Embedding(n_users, 1)
self.movie_factors = Embedding(n_movies, n_factors)
self.movie_bias = Embedding(n_movies, 1)
self.y_range = y_range
def forward(self, x):
users = self.user_factors(x[:,0])
movies = self.movie_factors(x[:,1])
res = (users * movies).sum(dim=1, keepdim=True)
res += self.user_bias(x[:,0]) + self.movie_bias(x[:,1])
return sigmoid_range(res, *self.y_range)思来想去还是教材中的图效果最好,模型就是给了每个movie5个factor给了每个user5个factor,还引入了偏差,这些值开始是随机的,训练完成之后就有意义了,最后sigmoid_range把user.factor和movie.factor的点集转为(0, 5.5)的范围
权值衰减
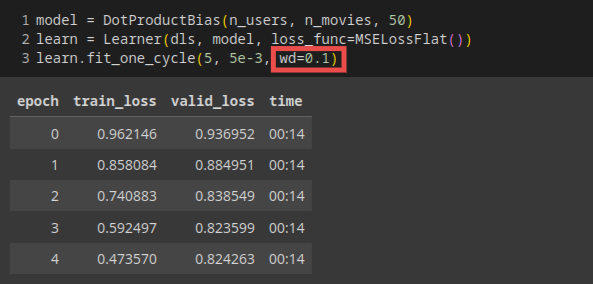
权重衰减,或者说L2正则化,是在你的损失函数中加入所有权重的平方和。为什么这样做呢?因为当我们计算梯度时,它会增加一个对梯度的贡献,这将鼓励权重尽可能地小。这会阻碍模型的训练,但它会产生一个更好的泛化状态。
调用fastai的api可以一步完成
解读Embeddings and Biases
biases(偏见)很好理解, 比如即使你通常不喜欢侦探电影,你可能会喜欢Gosick.直接解读Embeddings(嵌入矩阵)并不那么容易.对于人类来说,需要考虑的因素实在太多.但是,有一种可以从这样的矩阵中提取出最重要的基本方向的技术,叫做主成分分析(PCA).
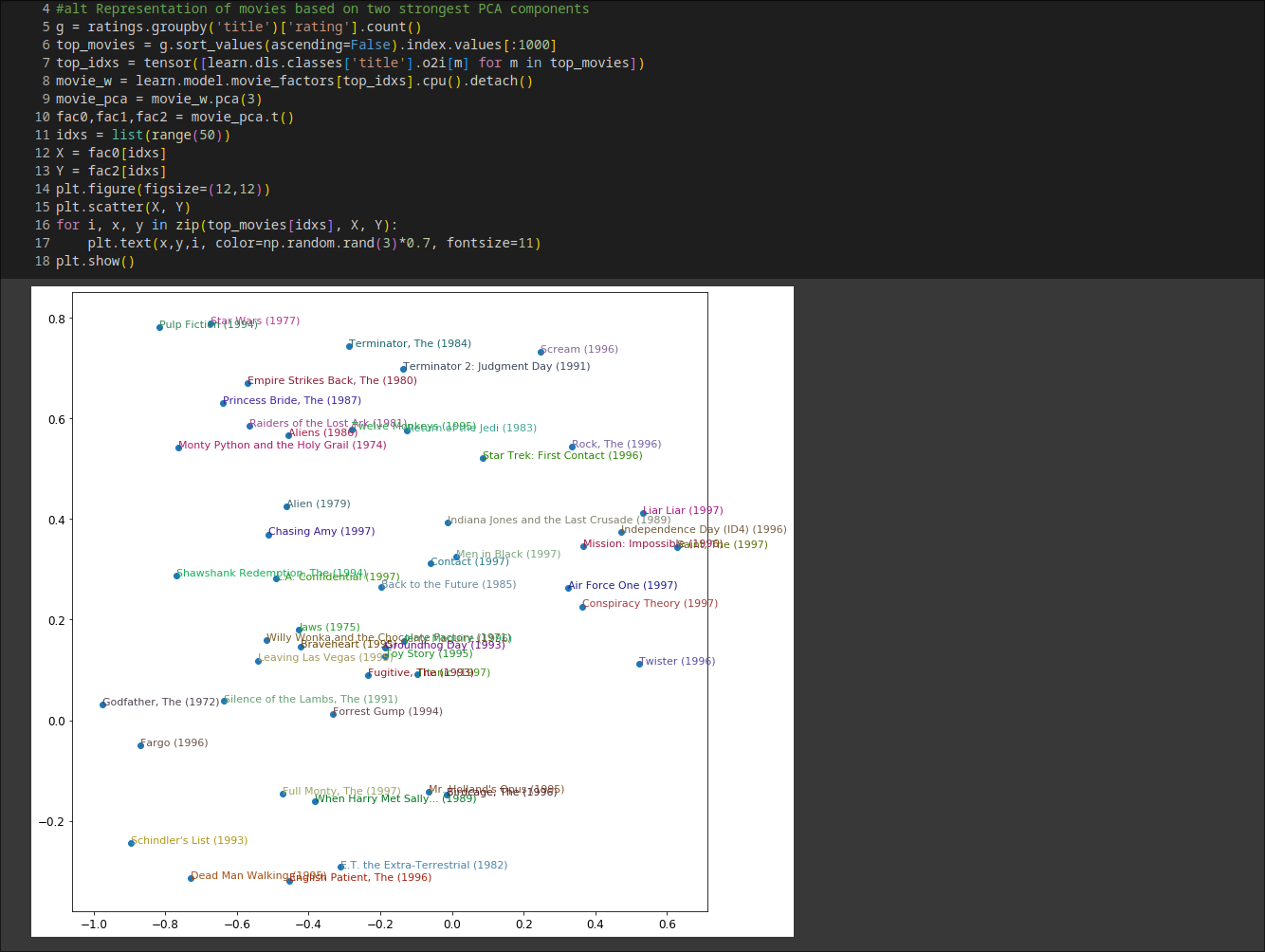
结论: 似乎发现了经典电影与流行文化电影的概念,这里暂时知道有PCA技术可以做这个事情就好
使用fastai.collab
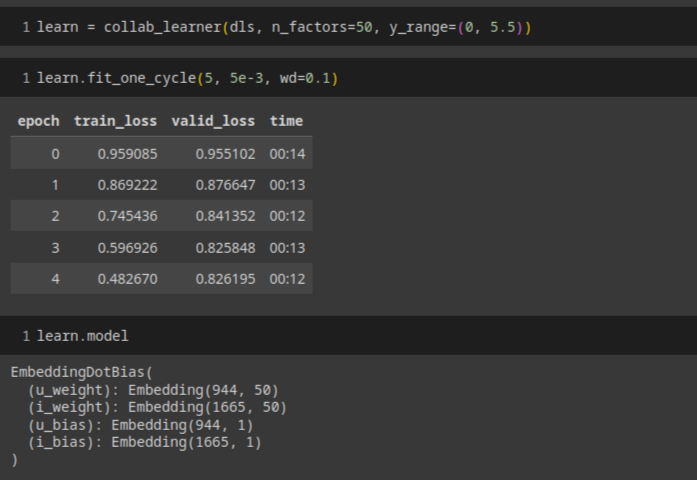
嵌入距离
用\[\sqrt{x^2+y^2}\]来找相似的电影
引导协同过滤模型
这个是为了处理新用户还没有用户数据时的情况
- 为新用户分配所有其他用户的嵌入向量的平均值
- 选择某个特定的用户来代表平均口味
- 基于用户元数据的表格模型来构建初始嵌入向量(问几个问题理解他们的口味)
- 少数极度热情的用户可能最终实际上为你的整个用户群体设定了推荐.例如看动漫的人往往会看很多动漫,而不会看很多其他的东西,并且花很多时间在网站上打分.
在这样的自我强化系统中,我们可能应该期望这种反馈循环是常态,而不是例外。因此,你应该假设你会看到它们,为此做好计划,并提前确定你将如何处理这些问题。试着思考所有可能在你的系统中出现的反馈循环,以及你可能如何在你的数据中识别它们。最后,这又回到了我们最初的建议,关于如何在推出任何类型的机器学习系统时避免灾难。这一切都是为了确保有人在循环中;有仔细的监控,以及逐步和深思熟虑的推出。
深度学习中的协同过滤
由于我们将会连接嵌入,而不是取它们的点积,这两个嵌入矩阵可以有不同的大小.
直接看代码实现
class CollabNN(Module):
def __init__(self, user_sz, item_sz, y_range=(0,5.5), n_act=100):
self.user_factors = Embedding(*user_sz)
self.item_factors = Embedding(*item_sz)
self.layers = nn.Sequential(
nn.Linear(user_sz[1]+item_sz[1], n_act),
nn.ReLU(),
nn.Linear(n_act, 1))
self.y_range = y_range
def forward(self, x):
embs = self.user_factors(x[:,0]),self.item_factors(x[:,1])
x = self.layers(torch.cat(embs, dim=1))
return sigmoid_range(x, *self.y_range)由于我们将会连接嵌入,而不是取它们的点积,这两个嵌入矩阵可以有不同的大小
fastai有一个函数 get_emb_sz ,它根据fast.ai在实践中发现的经验法则,为你的数据返回推荐的嵌入矩阵大小.
*embs表示将embs这个可迭代对象拆分成单独的参数传递给函数。**kwargs用于接收任意数量的关键字参数,并将这些关键字参数传递给TabularModel类的构造函数。
