
开此帖记录一下心得

youtube视频看了两节视频,觉得看jupyter notebook更适合自己
沉浸式翻译的插件配合从gemini免费申请的api,阅读毫无障碍

官方ipynb文件的字太多了,昨天看了一天好累,虽然有在看完之后复现一下主要代码,但是大部分时间没有写代码会无聊死的,而且效果很不好,现在是在colab另外开一个文档跟着复现代码,不再关注文字部分,只会在有不理解的地方回过头看文字的解释,效果好很多,另外有好多我很喜欢的概念和思想,想单独记录
我好想悟了,不需要去钻得太深,fastai在pytorch之上,省略了很多自己构建的过程,明白它针对不同任务的策略就行.
每天都要夸一夸,fastai真的让我这样没有什么资源,不愿花时间等模型训练几个小时的人玩到了神经网络.
GPU只有在并行执行大量相同的工作时才有用
最近两篇post 09,10写的很水,先不要往前看了吧,回过头做个小项目巩固一下,而且收了一个v6的大盘鸡还没时间倒腾,接下来是 happy code!
做了一个语音情绪识别的小项目, 发现以前写的blog真是一点用都没有呢, 只是在当时理清思路有用, 后续会考虑新开一个帖子, 写下数据预处理, 训练模型, 部署到生产环境各步骤的总结, 方便以后翻阅.
现在回过头来看不过如此, 不过帮我顺利完成了几个实验倒是真的
fastai02-Production
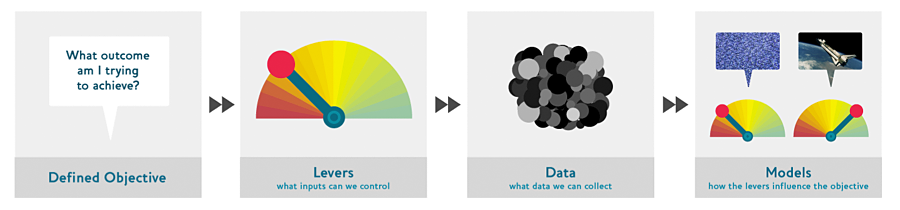
我们也建议你在项目中从头到尾进行迭代;也就是说,不要花费几个月的时间来微调你的模型,或者打磨完美的图形用户界面,或者标注完美的数据集……相反,你应该在合理的时间内尽可能完善每一个步骤,一直到最后。
首先考虑你的目标,然后思考你可以采取什么行动来实现这个目标,以及你拥有(或可以获取)哪些可以帮助的数据,然后构建一个模型
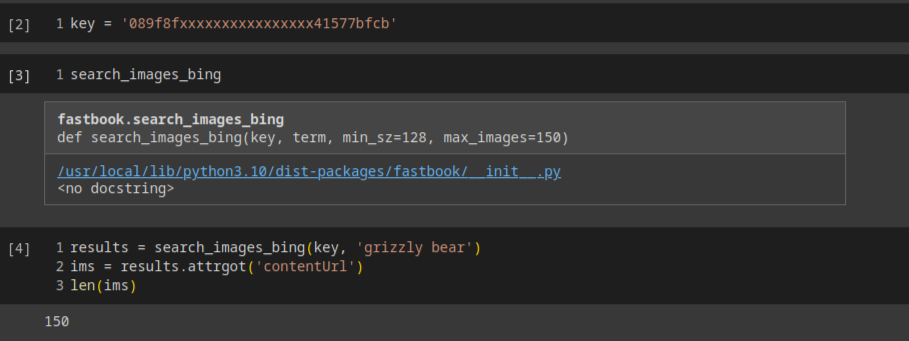
下载数据集
这里介绍了一个很新颖的获取数据的方式,用bing的图片搜索api去获取数据集,并清除下载失败的数据,详见附录文件
DataLoaders | 数据加载器
# 下述参数的解释在官方教程里解释得很清楚
bears = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=Resize(128))要将我们下载的数据转化为一个 DataLoaders 对象,至少需要告诉fastai四件事
- 我们正在处理哪些类型的数据
- 如何获取物品列表
- 如何标记这些项目
- 如何创建验证集
我们不是一次喂给模型一张图像,而是几张.为了将它们组合在一个大数组(张量)中,这个数组将通过我们的模型,它们都需要具有相同大小.所以,我们需要添加一个转换,将这些图像调整到相同的大小.fastai包含了许多预定义的转换,包括裁剪,填充,拉伸等等.
数据增强
数据增强是指创建我们的输入数据的随机变化,使它们看起来不同,但实际上并不改变数据的含义。常见的图像数据增强技术包括旋转、翻转、透视变形、亮度变化和对比度变化。

直观的数据清理方法是在训练模型之前进行。但是,正如你在这个案例中看到的,模型实际上可以帮助你更快更容易地发现数据问题。所以,我们通常更倾向于先训练一个快速简单的模型,然后用它来帮助我们进行数据清理。
一些方便的功能
混淆矩阵

查看loss最高的样本

数据清理工具

从模型创建notebook应用
通过ipywidgets,我们可以逐步构建我们的图形用户界面.最终界面是这个样子

将notebook转化为真正的应用程序
生成.py文件
由于软件包的更新,在实际复现过程中发现了几个问题,就不一一展示,当前的ipynb实例文件在文末,从'#|default_exp foo'开始, 最后执行下面这个脚本代码会自动生成foo.py文件,注释都是不能省的.
from nbdev.export import nb_export
nb_export('/content/gdrive/MyDrive/Colab Notebooks/Untitled8.ipynb', '.' )部署到huggingface space

然后照着教程push就好,只需要注意一个地方
git clone https://huggingface.co/spaces/username/bear
# 在push的时候是需要认证的,username+password的方式已被弃用,只能通过token认证,虽然clone之后也可以添加token,但是建议在clone时就加上
git clone https://username:your_token@huggingface.co/spaces/username/bear添加app.py(上文中的foo.py), requiremens.txt,packages.txt(添加Debian 依赖项),example.plk和example.jpg等文件,再重新push就好
fastai
gradiorequiremens.txt
安装git-lfs参考这个


04-Training a Digit Classifier
05-Pet Breeds
额,这章的结尾有点草率啊.主要介绍了图像的预处理,交叉熵损失,学习率的查找
预处理
- 第一步,调整大小,创建足够大的图像,以便它们有足够的边距,以便在内部区域进行进一步的增强变换,而不会创建空区域。此变换通过使用较大的裁剪大小调整为正方形来工作。在训练集上,裁剪区域是随机选择的,并且裁剪的大小被选择为覆盖图像的整个宽度或高度,以较小者为准。
- 性能要求表明,我们应该尽可能将增强变换(如旋转,缩放,剪切等)组合成更少的变换(以减少计算次数和有损操作次数),并将图像转换为统一大小.
交叉熵损失
算了,代码复现完了就行,懒得记了,反正也不会再看,下次边看边记吧.
fastai06-Muticat
多标签分类问题

如图,图片-->多标签分类,数据集是这样的

观察labels的特点我们发现,labels的种类有猫,狗,自行车,飞机多种, 且一张图片中可能有多个种类,为此我们对labels采取one-hot编码
One-hot 编码
以前只有两类猫和狗,用0,1编码就够了,现在出现了dog, car, bird, cat, ...多个种类,而且在一张图片中可能出现多种种类(如下图),而PyTorch 需要张量,其中所有内容的长度都必须相同.所以使用词汇表到one-hot映射这种编码方式

一捆数据的激活是这样的

了解如何手动获取小批量并将其传递到模型中,并查看激活和丢失,对于调试模型非常重要。这对学习也非常有帮助,这样你就可以准确地看到发生了什么。
partial函数
它允许我们将函数与一些参数或关键字参数绑定,从而创建该函数的新版本,无论何时调用它,它总是包含这些参数。通过示例很好理解

计算损失时变化不大
def binary_cross_entropy(inputs, targets):
inputs = inputs.sigmoid()
return -torch.where(targets==1, inputs, 1-inputs).log().mean()在预测时引入阈值,我感觉这个阈值不会影响loss吧,但是会影响正确率,可以在训练完了之后用下面的方法找合适的阈值

回归问题

图像-->点坐标, 需要注意在数据增强的过程中点坐标也要数据增强,另外在创建学习器时指定了y的范围
learn = vision_learner(dls, resnet18, y_range=(-1,1))它是根据下面这个函数实现的

然后寻找lr, 训练并展示结果,看起来fastai自动的帮我们完成了大量的工作

fastai07-Sizing and Tta
本章主要是介绍了几种先进技术
Normalization | 归一化
这个在 Andrej Karpathy的视频里讲得更清楚


fastai先是给出了结论
在训练模型时,如果输入数据被归一化(即均值为 0,标准差为 1),训练效果会更好。
然后给了一个例子, 对比了有批量归一化层和没有批量归一化层,其实效果差不多,但是
虽然它在这里只起了一点作用,但在使用预训练模型时,归一化变得尤为重要。预训练模型只知道如何处理它以前见过的类型的数据。如果用于训练的数据中的平均像素值为 0,但您的数据将 0 作为像素的最小可能值,那么模型将看到与预期截然不同的内容!
Progressive Resizing | 渐进式调整大小
基本思想
从小图像开始训练,然后使用大图像结束训练。将大部分时间花在小图像上训练,有助于更快地完成训练。使用大图像完成训练可以使最终精度更高。

Test Time Augmentation | 测试时间增强
基本思想
在推理或验证过程中,使用数据增强创建每个图像的多个版本,然后对每个增强版本的图像的预测结果取平均值或最大值。
preds,targs = learn.tta()
accuracy(preds, targs).item()Mixup | 混合
一张图说明一切
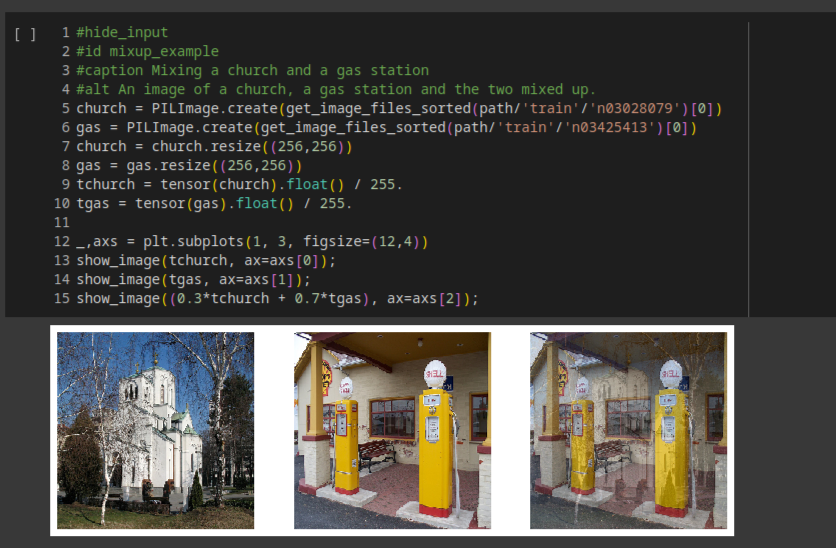
第三张图像是通过加上第一张图像的0.3倍和第二张图像的0.7倍构建的.假设我们有10个类别,"教堂"由索引2表示,"加油站"由索引7表示,那么one-hot编码的表示是:
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0] and [0, 0, 0, 0, 0, 0, 0, 1, 0, 0]因此我们的目标target是
[0, 0, 0.3, 0, 0, 0, 0, 0.7, 0, 0]因为我们在每个周期中展示的不是同一张图片,而是两张图片的随机组合,Mixup可以有效的防止过拟合.另外Mixup帮我们处理了另一个微妙的问题,那就是我们以前看到的模型实际上无法使我们的损失完美.原因在于我们的标签是1和0,但是softmax和sigmoid的输出永远不能等于1或0.这意味着训练我们的模型会使我们的激活值越来越接近这些值,以至于我们做的epoch越多,我们的激活值就会变得越极端.
Label Smoothing | 标签平滑
基本思想
你的数据永远不会完美.我们可以用稍小于1的数替换所有的1,用稍大于0的数替换所有的0,然后进行训练。这就叫做标签平滑。通过鼓励你的模型不要过于自信,标签平滑会使你的训练更加稳健,即使存在标签错误的数据。结果将是一个泛化能力更强的模型。
具体替换规则是这样的.用 ϵ/N 替换所有的0,其中 N 是类别的数量, ϵ 是一个参数(通常为0.1,这意味着我们对我们的标签有10%的不确定性).由于我们希望标签的总和为1,所以将1替换为 1−ϵ+ϵN.
[0.01, 0.01, 0.01, 0.91, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01]fastai08-collab
协同过滤
协同过滤,它的工作方式是这样的:看看当前用户使用或喜欢的产品,找到使用或喜欢类似产品的其他用户,然后推荐那些用户使用或喜欢的其他产品。
我们假设评价一个电影有三个因素,factor1, factor2, factor3,1代表非常匹配,-1代表非常不匹配,那么movie1用数组这样表示
movie1 = np.array([0.98,0.9,-0.9])用户对这三个factor的匹配度
user1 = np.array([0.9,0.8,-0.6])计算这个组合的匹配度
(user1*movie1).sum()2.1420000000000003
数据是这样的
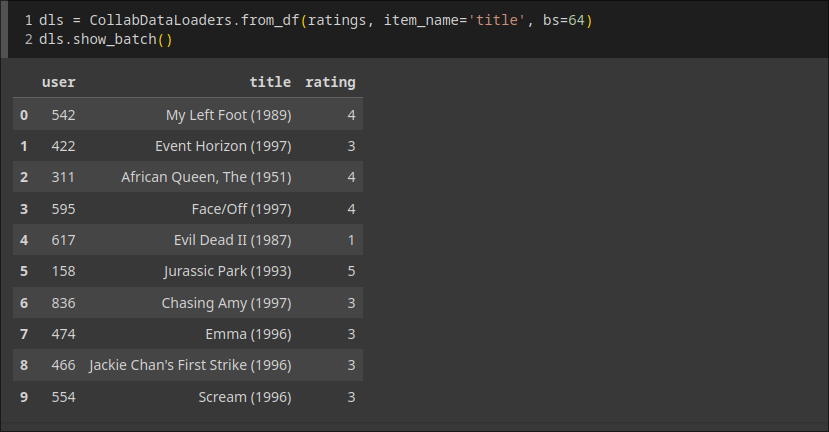
我们将为我们的每个用户和每部电影分配一个特定长度(这里是 n_factors=5 )的随机向量,并将这些作为可学习的参数在开始时,这些数字并没有任何意义,因为我们是随机选择的,但到训练结束时,它们就有了意义.网络结构是这样的
class DotProductBias(Module):
def __init__(self, n_users, n_movies, n_factors, y_range=(0,5.5)):
self.user_factors = Embedding(n_users, n_factors)
self.user_bias = Embedding(n_users, 1)
self.movie_factors = Embedding(n_movies, n_factors)
self.movie_bias = Embedding(n_movies, 1)
self.y_range = y_range
def forward(self, x):
users = self.user_factors(x[:,0])
movies = self.movie_factors(x[:,1])
res = (users * movies).sum(dim=1, keepdim=True)
res += self.user_bias(x[:,0]) + self.movie_bias(x[:,1])
return sigmoid_range(res, *self.y_range)思来想去还是教材中的图效果最好,模型就是给了每个movie5个factor给了每个user5个factor,还引入了偏差,这些值开始是随机的,训练完成之后就有意义了,最后sigmoid_range把user.factor和movie.factor的点集转为(0, 5.5)的范围
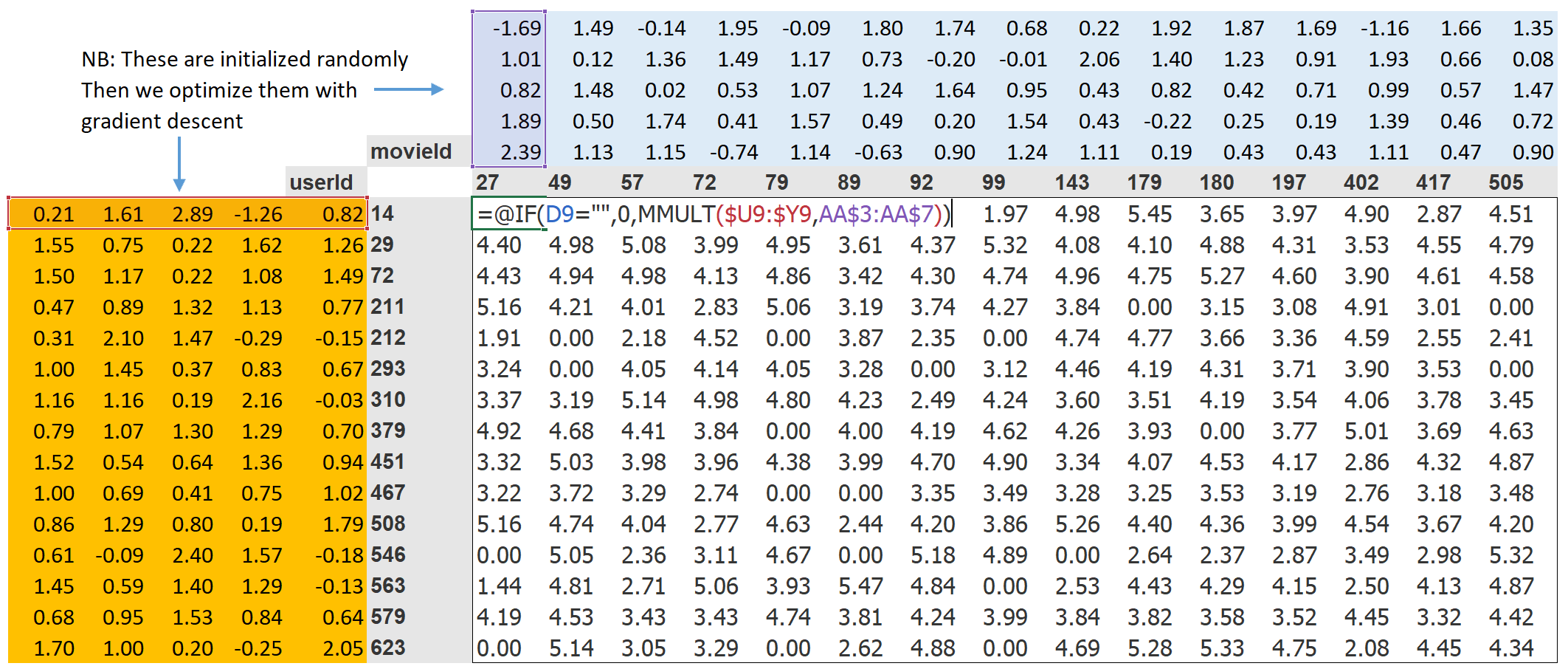
权值衰减
权重衰减,或者说L2正则化,是在你的损失函数中加入所有权重的平方和。为什么这样做呢?因为当我们计算梯度时,它会增加一个对梯度的贡献,这将鼓励权重尽可能地小。这会阻碍模型的训练,但它会产生一个更好的泛化状态。
调用fastai的api可以一步完成
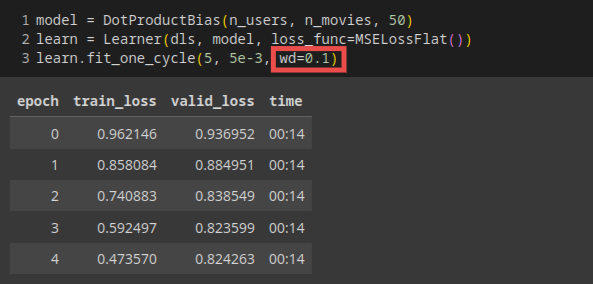
解读Embeddings and Biases
biases(偏见)很好理解, 比如即使你通常不喜欢侦探电影,你可能会喜欢Gosick.直接解读Embeddings(嵌入矩阵)并不那么容易.对于人类来说,需要考虑的因素实在太多.但是,有一种可以从这样的矩阵中提取出最重要的基本方向的技术,叫做主成分分析(PCA).
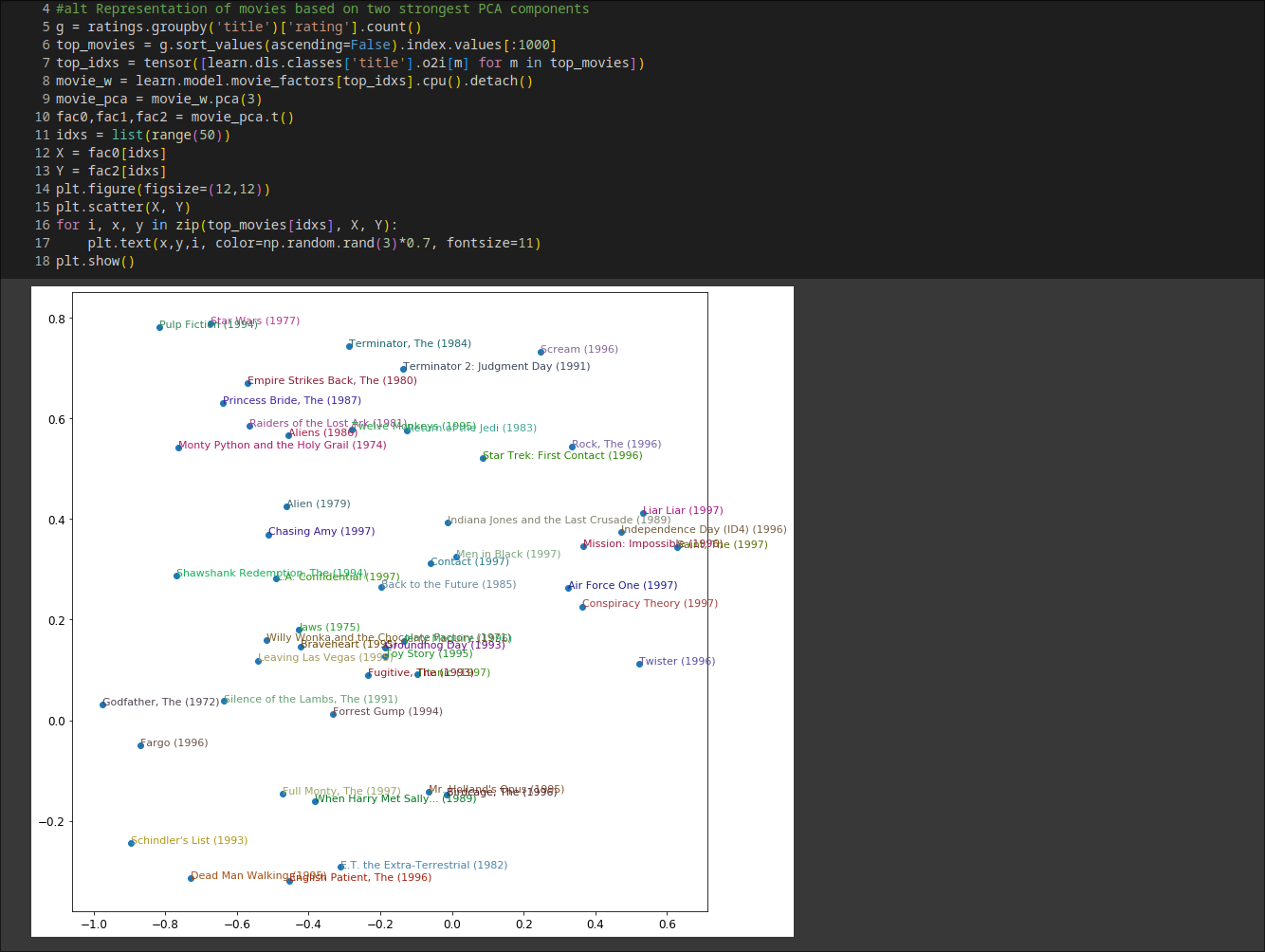
结论: 似乎发现了经典电影与流行文化电影的概念,这里暂时知道有PCA技术可以做这个事情就好
使用fastai.collab
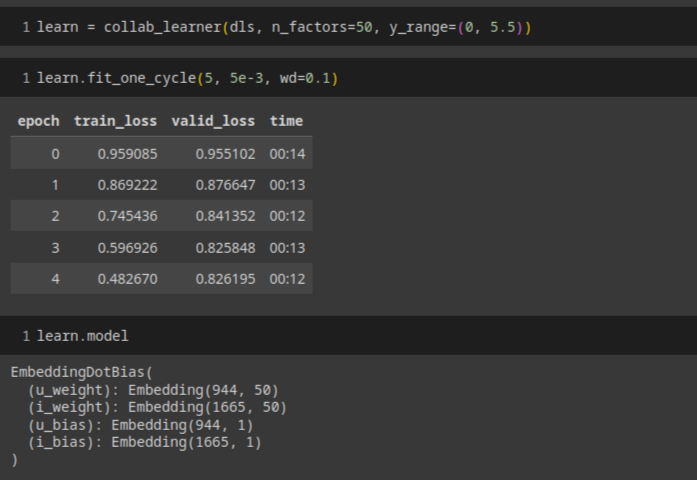
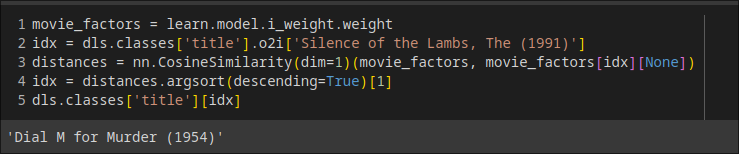
嵌入距离
用\[\sqrt{x^2+y^2}\]来找相似的电影
引导协同过滤模型
这个是为了处理新用户还没有用户数据时的情况
- 为新用户分配所有其他用户的嵌入向量的平均值
- 选择某个特定的用户来代表平均口味
- 基于用户元数据的表格模型来构建初始嵌入向量(问几个问题理解他们的口味)
- 少数极度热情的用户可能最终实际上为你的整个用户群体设定了推荐.例如看动漫的人往往会看很多动漫,而不会看很多其他的东西,并且花很多时间在网站上打分.
在这样的自我强化系统中,我们可能应该期望这种反馈循环是常态,而不是例外。因此,你应该假设你会看到它们,为此做好计划,并提前确定你将如何处理这些问题。试着思考所有可能在你的系统中出现的反馈循环,以及你可能如何在你的数据中识别它们。最后,这又回到了我们最初的建议,关于如何在推出任何类型的机器学习系统时避免灾难。这一切都是为了确保有人在循环中;有仔细的监控,以及逐步和深思熟虑的推出。
深度学习中的协同过滤
由于我们将会连接嵌入,而不是取它们的点积,这两个嵌入矩阵可以有不同的大小.
直接看代码实现
class CollabNN(Module):
def __init__(self, user_sz, item_sz, y_range=(0,5.5), n_act=100):
self.user_factors = Embedding(*user_sz)
self.item_factors = Embedding(*item_sz)
self.layers = nn.Sequential(
nn.Linear(user_sz[1]+item_sz[1], n_act),
nn.ReLU(),
nn.Linear(n_act, 1))
self.y_range = y_range
def forward(self, x):
embs = self.user_factors(x[:,0]),self.item_factors(x[:,1])
x = self.layers(torch.cat(embs, dim=1))
return sigmoid_range(x, *self.y_range)由于我们将会连接嵌入,而不是取它们的点积,这两个嵌入矩阵可以有不同的大小
fastai有一个函数 get_emb_sz ,它根据fast.ai在实践中发现的经验法则,为你的数据返回推荐的嵌入矩阵大小.
*embs表示将embs这个可迭代对象拆分成单独的参数传递给函数。**kwargs用于接收任意数量的关键字参数,并将这些关键字参数传递给TabularModel类的构造函数。

fastai09-Tabular
表格建模以表格形式接收数据(如电子表格或CSV)。其目标是基于其他列中的值来预测一列中的值。
决策树集合是我们分析新的表格数据集的首选方法。
满足以下条件之一时适合使用神经网络的方法
1. 存在一些高基数的分类变量非常重要("基数"指的是代表类别的离散级别的数量,所以高基数的分类变量就像邮政编码,可以有数千种可能的级别)。
2. 有些列包含的数据最好通过神经网络来理解,比如纯文本数据。
大多数机器学习课程会向你介绍几十种不同的算法,简要解释它们背后的数学原理,可能还会给一个玩具示例。你会被展示的大量技术茫然不知所措,对如何应用它们几乎没有实际理解。
数据集清洗
fastai使用TabularPandas 和 TabularProc清理数据特别方便,详见附录.ipynb文件.
分类变量
结合两张图很好理解, 就是把各类别排序并且用一个数字表示

创建决策树


随机森林
尽管在数据子集上训练的每个模型会比在完整数据集上训练的模型产生更多错误,但这些错误不会相互关联。不同的模型会产生不同的错误。因此,这些错误的平均值是:零!因此,如果我们取所有模型预测的平均值,那么我们应该得到一个预测,随着模型数量的增加,它会越来越接近正确答案。
基本思想是假设这里有n块区域,每块区域都抽取完整训练集的一部分来创建决策树.当要预测某个样本时,让样本用每个决策树进行预测,取结果的平均值.
袋外误差 | Out-of-Bag Error
我的直觉是,由于每棵树都是用不同的随机选择的行子集进行训练,所以袋外误差有点像想象每棵树也有自己的验证集。该验证集就是那些没有被选中用于该树训练的行。
预测置信度的树方差
我们对使用特定数据行进行预测有多大信心?
这里的方法是让验证集在每一棵树上得到验证, 计算样本在每棵树上验证的结果的偏差,偏差越大,树的预测越不一致.
特征重要性
对于预测特定数据行,最重要的因素是什么,它们是如何影响该预测的?
评价上述问题的指标就是特征重要性.特征重要性算法遍历每一个树的每一个节点,查看该节点的特征是什么,然后给该特征一个改善值(与改组的样本数量有关),这些值在所有树的所有分支中求和,最终将分数归一化,使其总和为1.
这里有点没弄懂,下面是我的猜测.对于下面这个简单的决策树, 我们可以看到根节点有404710个样本,这个节点的特征是Coupler_System,那么模型因为Coupler_System的改善值可能与分裂前的value10.1和分裂后的value=10.21, 9.21有关,改善值乘以样本数404710被添加到Coupler_System的重要性分数中.遍历所有节点,将分数归一化就得到各特征的重要性分数.同样现代库要算这个很简单,见附录.ipynb文件.

其他的几种处理数据的方法
- 去除低重要性变量

- 去除冗余特征

特征依赖
它是为了搞懂这样一个问题
如果一行数据除了感兴趣的特征之外没有变化,那么它会如何影响因变量?
假如要要确定"其他条件相同的情况下, YearMade 会对销售价格产生什么影响".用1950替换 YearMade 列中的每个值,然后计算每次拍卖的预测销售价格,并对所有拍卖进行平均.然后我们对1951年,1952年等进行相同操作,直到我们的最终年份2011年.

信息泄漏
下面是一个很好的例子
Jeremy使用随机森林对数据进行建模,然后使用特征重要性来找出哪些特征具有最强的预测能力。他注意到了三件令人惊讶的事情:
1. 该模型能够在95%以上的时间内正确预测谁将获得资助。
2. 显然毫无意义的标识列是最重要的预测因素。
3. 星期几和一年中的日期列也具有很高的预测性;例如,大多数在星期日日期的资助申请被接受,而许多被接受的资助申请日期为1月1日。
对于标识列,每列一个部分依赖图显示,当信息缺失时,申请几乎总是被拒绝。实际上,大学只在资助申请被接受后填写了大部分这些信息。通常,对于未被接受的申请,这些信息只是留空。因此,这些信息实际上在申请接收时并不可用,并且不会对预测模型可用——这是数据泄漏。
树解释器
为了回答这个问题
对于预测特定数据行,最重要的因素是什么,它们是如何影响该预测的?
用瀑布图展示贡献是最清晰的方式.

外推问题 | The Extrapolation Problem
随机森林只是对多棵树的预测结果进行平均。而一棵树只是预测叶子中行的平均值。因此,一棵树和一个随机森林永远无法预测超出训练数据范围的值。

寻找领域外数据
这里我只能复述它的思路, 它将训练集和验证集合并在一起,构建了一个判断每行是否为验证集的随机森林.从特征重要性的指标中发现训练集和验证集之间有三列存在显著差异: saleElapsed , SalesID 和 MachineID .然后分别剔除这三者算均方差损失,发现能够移除 SalesID 和 MachineID 而不会失去任何准确性.

使用神经网络
见附录.ipynb
一些先进的技术
集成 | Ensembling
使用多个模型并平均它们的预测结果,这种技术被称为集成。
例如随机森林和神经网络的集成模型
提升 | boosting
- 训练一个欠拟合你的数据集的小模型。
- 计算该模型在训练集中的预测。
- 从目标值中减去预测值;这些被称为“残差”,代表训练集中每个点的误差。
- 回到第一步,但是不要使用原始目标,而是使用残差作为训练的目标。
- 继续执行此操作,直到达到某个停止准则,比如最大树数量,或者观察到验证集错误变得更糟。
使用提升树集成进行预测时,我们计算每棵树的预测值,然后将它们相加。
将嵌入与其他方法结合
从训练好的神经网络中获得的嵌入,在作为输入特征时显著提升了所有测试过的机器学习方法的性能

建议
- 随机森林是最容易训练的,因为它们对超参数选择非常弹性,并且需要很少的预处理。它们训练速度很快,如果有足够的树,不应该过拟合。但它们可能会略微不够准确,特别是在需要外推的情况下,比如预测未来时间段。
- 在理论上,梯度提升机的训练速度与随机森林相同,但在实践中,您将不得不尝试许多不同的超参数。它们可能会过拟合,但通常比随机森林更准确。
- 神经网络需要最长的训练时间,并且需要额外的预处理,比如归一化;这种归一化在推断时也需要使用。它们可以提供很好的结果并且能够很好地外推,但只有在您小心处理超参数并避免过拟合时才能实现。
我们建议从随机森林开始分析。这将为您提供一个强大的基准线,您可以确信这是一个合理的起点。然后,您可以使用该模型进行特征选择和部分依赖分析,以更好地理解您的数据。
从这个基础上,你可以尝试神经网络和GBM,如果它们在合理的时间内在验证集上给出了显著更好的结果,你可以使用它们。如果决策树集成对你有很好的效果,尝试将分类变量的嵌入添加到数据中,看看这是否有助于决策树学习得更好。

fastai10-NLP
Andrej Karpathy 有一个专栏专门介绍NLP(chat GPT)


在将语言模型转移到分类任务之前,对语言模型进行额外的微调阶段,会导致预测结果显著提高。
文本预处理
我们几乎可以用处理分类变量的方法处理文本, 新的想法是序列的概念.
- 将数据集中的所有文档连接成一个非常长的字符串
- 将其分割成单词, 这样我们就得到了一个非常长的单词列表(或"标记")
- 自变量是我们的长列表中从第一个单词开始到倒数第二个单词结束的单词序列,而因变量将是从第二个单词开始到最后一个单词结束的单词序列
分词
- 基于单词的:将句子按空格分割,并应用特定于语言的规则尝试在无空格的情况下分离意义的部分(例如将"don't"转换为"do n't").通常,标点符号也被分割成单独的标记.
- 基于子词的:将单词分解成更小的部分,基于最常见的子串.例如,"occasion"可能被标记为"o c ca sion".
- 基于字符的:将句子分解为单个字符.
使用fastai进行词条化
Before Jim Davis got his last and career part as Jock Ewing in Dallas, he h示例
['Before','Jim','Davis','got','his','last','and','career','part','as','Jock','Ewing','in','Dallas',',','he','had','one','tortured','path','to','Hollywood','success','.','He','had','a','much','publicized','debut'...]spacy库分词结果
['xxbos','xxmaj','before','xxmaj','jim','xxmaj','davis','got','his','last','and','career','part','as','xxmaj','jock','xxmaj','ewing','in','xxmaj','dallas',',','he','had','one','tortured','path','to','xxmaj','hollywood','success'...]fastai分词结果
xxbos表示文本的开始xxmaj表示下一个单词以大写字母开头xxunk表示该词未知
主要功能简要说明
fix_html将特殊HTML字符替换为可读版本(IMDb评论中有不少这样的字符)replace_rep将任何重复三次或更多的字符替换为重复的特殊标记(xxrep),然后是重复的次数,最后是该字符replace_wrep将任何重复三次或以上的单词替换为表示单词重复的特殊标记(xxwrep),然后是该单词重复的次数,最后是该单词spec_add_spaces添加空格在 / 和 # 周围rm_useless_spaces移除所有空格字符的重复replace_all_caps将全大写的单词转换为小写,并在其前面添加一个全大写的特殊标记(xxup)replace_maj将大写字母转换为小写,并在其前面添加一个特殊标记,表示大写(xxmaj)lowercase将所有文本转换为小写,并在开头(xxbos)和/或结尾(xxeos)添加特殊标记
这些规则给人的感受是如果不这样做,训练的时候肯定会出问题
子词分词
效果图
子词分词提供了一种在字符分词(即使用小字符词汇)和词分词(即使用大字符词汇)之间轻松扩展的方法,并且无需开发特定于语言的算法即可处理所有人类语言。它甚至可以处理其他“语言”,例如基因序列或MIDI音乐符号!因此,在过去一年中,它的受欢迎程度飙升,并且似乎很可能成为最常见的分词方法(到您阅读本文时,它可能已经是了!)。
使用fastai进行数值化
这个截屏软件输不了中文
将我们的文本分批用于语言模型
小插曲:看起来deepseek的语言模型词汇表中也使用了xxbos的标签
直接看我们实现的效果

训练文本分类器
文本生成
注意,前面只是引言,从这个地方实际应该重新思考NLP问题--用fastai的方式.实际上感觉不到训练BLP和之前分类问题,表格问题的不同
# 使用 TextBlock 来创建语言模型
get_imdb = partial(get_text_files, folders=['train', 'test', 'unsup'])
dls_lm = DataBlock(
blocks=TextBlock.from_folder(path, is_lm=True),
get_items=get_imdb, splitter=RandomSplitter(0.1)
).dataloaders(path, path=path, bs=128, seq_len=80)learn = language_model_learner(
dls_lm, AWD_LSTM, drop_mult=0.3,
metrics=[accuracy, Perplexity()]).to_fp16()learn.fit_one_cycle(1, 2e-2)# 一旦初始训练完成,我们可以在解冻后继续对模型进行微调
learn.unfreeze()
learn.fit_one_cycle(10, 2e-3)learn.save_encoder('finetuned')编码器:不包括特定任务的最终层(们)的模型。这个词在应用于视觉CNN时与“主体”大致相同,但“编码器”在NLP和生成模型中更常用。
到此我们完成的是一个语言生成模型,给它一些关键词就可以开始生成文本, 下面我们将用这个模型
创建分类器数据加载器
它最后这儿的这个操作我没太弄懂, 所以回到了这章节最前面的介绍,有这样的一句话
对于IMDb情感分析任务,数据集包括50,000个额外的电影评论,这些评论没有附带任何正面或负面的标签。由于训练集中有25,000个标记的评论,验证集中有25,000个,总共就有100,000个电影评论。我们可以使用所有这些评论来微调预训练的语言模型,该模型仅在维基百科文章上进行训练;这将得到一个特别擅长预测电影评论下一个单词的语言模型。
这里提到有50000个额外的电影评论没有标签,前面的文本生成器可以用这50000个电影评论进行训练,让它很擅长预测电影评论的下一个单词?然后我再往后看,发现文本生成模型在这里的角色是"编码器"
这里也是创建分类器然后微调,不同在于
使用有区别的学习率和逐步解冻进行训练。在计算机视觉中,我们通常会一次性解冻模型,但对于NLP分类器,我们发现一次解冻几层确实有所不同
总结
在本章中,我们探索了fastai库开箱即用的最后一个应用:文本。我们看到了两种类型的模型:可以生成文本的语言模型,以及可以确定评论是正面还是负面的分类器。为了构建一个最先进的分类器,我们使用了一个预训练的语言模型,将其微调到我们任务的语料库中,然后使用其主体(编码器)与一个新的头来执行分类。

fastai11-Midlevel Data
fastai可以做到5行代码训练一个模型, 这也正是它吸引我的地方
from fastai.text.all import *
dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test')
path = untar_data(URLs.IMDB)
dls = DataBlock(
blocks=(TextBlock.from_folder(path),CategoryBlock),
get_y = parent_label,
get_items=partial(get_text_files, folders=['train', 'test']),
splitter=GrandparentSplitter(valid_name='test')
).dataloaders(path)但是它有时不够灵活, 这是就需要用到中级API
编写自己的Transform
class NormalizeMean(Transform):
def setups(self, items): self.mean = sum(items)/len(items)
def encodes(self, x): return x-self.mean
def decodes(self, x): return x+self.mean
tfm = NormalizeMean()
tfm.setup([1,2,3,4,5])
start = 2
y = tfm(start)
z = tfm.decode(y)
tfm.mean,y,zoutput: (3.0, -1.0, 2.0)
Pipeline | 管道
用于将多个转换组合在一起
# 分词再编码(数值化)
tfms = Pipeline([tok, num])
t = tfms(txts[0]); t[:20]tensor([ 2, 8, 76, 10, 23, 3112, 23, 34, 3113, ...])
TfmdLists
TfmdLists可以一次性执行所有的预处理操作, 将原始项目转换为具有输入和目标的元组.
cut = int(len(files)*0.8)
splits = [list(range(cut)), list(range(cut,len(files)))]
tls = TfmdLists(files, [Tokenizer.from_folder(path), Numericalize],
splits=splits)结论
下面的实现和文章开头的实现一致
tfms = [[Tokenizer.from_folder(path), Numericalize], [parent_label, Categorize]]
files = get_text_files(path, folders = ['train', 'test'])
splits = GrandparentSplitter(valid_name='test')(files)
dsets = Datasets(files, tfms, splits=splits)
dls = dsets.dataloaders(dl_type=SortedDL, before_batch=pad_input)一个计算机视觉的小例子
def label_func(fname):
return re.match(r'^(.*)_\d+.jpg$', fname.name).groups()[0]
class SiameseTransform(Transform):
def __init__(self, files, label_func, splits):
self.labels = files.map(label_func).unique()
self.lbl2files = {l: L(f for f in files if label_func(f) == l)
for l in self.labels}
self.label_func = label_func
self.valid = {f: self._draw(f) for f in files[splits[1]]}
def encodes(self, f):
f2,t = self.valid.get(f, self._draw(f))
img1,img2 = PILImage.create(f),PILImage.create(f2)
return SiameseImage(img1, img2, t)
def _draw(self, f):
same = random.random() < 0.5
cls = self.label_func(f)
if not same:
cls = random.choice(L(l for l in self.labels if l != cls))
return random.choice(self.lbl2files[cls]),same
splits = RandomSplitter()(files)
tfm = SiameseTransform(files, label_func, splits)
tls = TfmdLists(files, tfm, splits=splits)
dls = tls.dataloaders(after_item=[Resize(224), ToTensor],
after_batch=[IntToFloatTensor, Normalize.from_stats(*imagenet_stats)])
fastai12-NLP Dive
数据集


model1
没什么特别的, 就是输入的三个字符串是一个一个读取的, h记忆
hidden state 在循环神经网络的每一步中更新的激活
class LMModel1(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
def forward(self, x):
h = F.relu(self.h_h(self.i_h(x[:,0])))
h = h + self.i_h(x[:,1])
h = F.relu(self.h_h(h))
h = h + self.i_h(x[:,2])
h = F.relu(self.h_h(h))
return self.h_o(h)
model2
所谓循环神经网络(Recurrent Neural Network), 就是用for循环代替了前面的列举
class LMModel2(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
def forward(self, x):
h = 0
for i in range(3):
h = h + self.i_h(x[:,i])
h = F.relu(self.h_h(h))
return self.h_o(h)
model3
将隐藏状态的初始化移到了__init__(),使神经网络可以保存更多句子的信息, 但是我们又不希望当到达数据集的第10,000个单词时,神经网络仍然需要计算回溯到第一层的导数, 相反, 我们只保留最后三层的梯度. 在PyTorch中删除所有梯度历史记录, 我们使用 detach 方法.
# 保持RNN的状态
class LMModel3(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
self.h = 0
def forward(self, x):
for i in range(3):
self.h = self.h + self.i_h(x[:,i])
self.h = F.relu(self.h_h(self.h))
out = self.h_o(self.h)
self.h = self.h.detach()
return out
def reset(self): self.h = 0model4
之前是每三个词预测一个输出词, 这意味着我们更新权重的反馈信号量没有达到最大. 现在我们在每个词之后都预测下一个词, 这样更好
sl = 16
seqs = L((tensor(nums[i:i+sl]), tensor(nums[i+1:i+sl+1]))
for i in range(0,len(nums)-sl-1,sl))
cut = int(len(seqs) * 0.8)
dls = DataLoaders.from_dsets(group_chunks(seqs[:cut], bs),
group_chunks(seqs[cut:], bs),
bs=bs, drop_last=True, shuffle=False)
class LMModel4(Module):
def __init__(self, vocab_sz, n_hidden):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.h_h = nn.Linear(n_hidden, n_hidden)
self.h_o = nn.Linear(n_hidden,vocab_sz)
self.h = 0
def forward(self, x):
outs = []
for i in range(sl):
self.h = self.h + self.i_h(x[:,i])
self.h = F.relu(self.h_h(self.h))
outs.append(self.h_o(self.h))
self.h = self.h.detach()
return torch.stack(outs, dim=1)
def reset(self): self.h = 0model5
接着尝试使用多层RNN
class LMModel5(Module):
def __init__(self, vocab_sz, n_hidden, n_layers):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.rnn = nn.RNN(n_hidden, n_hidden, n_layers, batch_first=True)
self.h_o = nn.Linear(n_hidden, vocab_sz)
self.h = torch.zeros(n_layers, bs, n_hidden)
def forward(self, x):
res,h = self.rnn(self.i_h(x), self.h)
self.h = h.detach()
return self.h_o(res)
def reset(self): self.h.zero_()learn = Learner(dls, LMModel5(len(vocab), 64, 2),
loss_func=CrossEntropyLossFlat(),
metrics=accuracy, cbs=ModelResetter)
learn.fit_one_cycle(15, 3e-3)结果令人失望, 我们之前的单层RNN表现更好. 原因是我们的模型更深, 导致激活值爆炸或消失.
梯度爆炸或梯度消失
因为矩阵乘法只是乘以数字并把它们加起来, 重复的矩阵乘法也是如此. 这就是深度神经网络的全部——每个额外的层都是另一个矩阵乘法. 这意味着深度神经网络很容易最终得到非常大或非常小的数字.
计算机存储数字的方式(称为"浮点数")意味着随着数字离零越来越远, 它们的准确性会越来越低
长短期记忆 | LSTM
# 长短期记忆
# sigmoid: 0~1
# tanh : -1~1
"""
感性的理解
forget_gate: 遗忘门, 确定保留哪些信息和丢弃哪些信息:接近0的值被丢弃, 接近1的值被保留(sigmoid).
input_gate : 输入门, 也是决定更新单元状态的哪些元素, 但它和第三个门单元门一起工作
cell_gate : 单元门, 在输入门决定更新哪些元素之后, 它决定更新后的值是什么(tanh)
output_gate: 输出门, 决定从单元状态中提取哪些信息来生成输出
"""
class LSTMCell(Module):
def __init__(self, ni, nh):
self.forget_gate = nn.Linear(ni+nh, nh)
self.input_gate = nn.Linear(ni+nh, nh)
self.cell_gate = nn.Linear(ni+nh, nh)
self.output_gate = nn.Linear(ni+nh, nh)
def forward(self, input, state):
h, c = state
h = torch.cat([h, input], dim=1)
forget = torch.sigmoid(self.forget_gate(h))
c = c*forget
inp = torch.sigmoid(self.input_gate(h))
cell = torch.tanh(self.cell_gate(h))
c = c + inp * cell
out = torch.sigmoid(self.output_gate(h))
h = out * torch.tanh(c)
return h, (h,c)敲了三遍, 但是也不能说完全理解了. 我觉得最好的方式还是看代码, 看数值在神经网络中怎么流动的.文章中有张图感觉不好理解就不贴了
# 重构只是为了加速计算
# 感觉这个更好理解
class LSTMCell(Module):
def __init__(self, ni, nh):
self.ih = nn.Linear(ni, 4*nh)
self.hh = nn.Linear(nh, 4*nh)
def forward(self, input, state):
h, c = state
gates = (self.ih(input) + self.hh(h).chunk(4, 1))
ingate, forgetgate, outgate=map(torch.sigmoid, gates[:3])
cellgate = gates[3].tanh()
c=(forgetgate*c) + ingate*cellgate
h=outgate*c.tanh()
return h, (h,c)# 双层LSTMCell
class LMModel6(Module):
def __init__(self, vocab_size, n_hidden, n_layers):
self.i_h = nn.Embedding(vocab_size, n_hidden)
self.rnn = nn.LSTM(n_hidden, n_hidden, n_layers, batch_first=True)
self.h_o = nn.Linear(n_hidden, vocab_size)
self.h = [torch.zeros(n_layers, bs, n_hidden) for _ in range(2)]
def forward(self, x):
res, h = self.rnn(self.i_h(x), self.h)
self.h = [h_.detach() for h_ in h]
return self.h_o(res)
def reset(self):
for h in self.h: h.zero_()训练结果还是有点过拟合, 引入正则化
循环神经网络,一般来说,很难训练,因为之前我们看到的激活和梯度消失问题。使用 LSTM(或 GRU)单元比使用普通的 RNN 更容易训练,但它们仍然非常容易过拟合。数据增强虽然是一种可能性,但在文本数据上使用不如在图像上频繁,因为在大多数情况下,它需要另一个模型来生成随机增强(例如,通过将文本翻译成另一种语言,然后再翻译回原始语言)。总的来说,文本数据的数据增强目前并不是一个充分探索的领域。
使用dropout正则化
我去银行了。出纳员一直在换,我问其中一个为什么。他说他不知道,但他们经常被调动。我猜这一定是因为需要员工之间的合作才能成功诈骗银行。这让我意识到,在每个例子中随机移除不同子集的神经元可以防止共谋,从而减少过拟合。
我们并不真正知道为什么神经元会放电。一种理论是,它们想要变得嘈杂,以便进行正则化,因为我们拥有的参数比数据点多得多。dropout 的想法是,如果你有嘈杂的激活,你就可以使用一个更大的模型。
这解释了为什么 dropout 有助于泛化的背后的想法:首先它帮助神经元更好地协同工作,然后它使激活更加嘈杂,从而使模型更加健壮。
class Dropout(Module):
def __init__(self, p):
self.p = p
def forward(self, x):
if not self.training: return x
mask = x.new(*x.shape).bernoulli_(1-self.p)
return x * mask.div_(1-self.p)训练一个权重绑定正则化的LSTM
class LMModel7(Module):
def __init__(self, vocab_sz, n_hidden, n_layers, p):
self.i_h = nn.Embedding(vocab_sz, n_hidden)
self.rnn = nn.LSTM(n_hidden, n_hidden, n_layers, batch_first=True)
self.drop = nn.Dropout(p)
self.h_o = nn.Linear(n_hidden, vocab_sz)
self.h_o.weight = self.i_h.weight
self.h = [torch.zeros(n_layers, bs, n_hidden) for _ in range(2)]
def forward(self, x):
raw, h = self.rnn(self.i_h(x), self.h)
out = self.drop(raw)
self.h = [h_.detach() for h_ in h]
return self.h_o(out), raw, out
def reset(self):
for h in self.h:
h.zero_()对于激活正则化(Activation regularization),我们试图使 LSTM 产生的最终激活尽可能小,而不是权重本身。
loss += alpha * activations.pow(2).mean()对于时间激活正则化(Temporal activation regularization), 我们希望两个连续激活之间的差异尽可能小
loss += beta * (activations[:,1:] - activations[:,:-1]).pow(2).mean()AR 通常应用于 dropout 的激活(以不惩罚我们随后将其变为零的激活),而 TAR 应用于非 dropout 的激活
我们可以从 AWD LSTM 论文中添加的另一个有用技巧是权重绑定。在语言模型中,输入嵌入表示从英语单词到激活的映射,而输出隐藏层表示从激活到英语单词的映射。我们可能会直观地认为这些映射可能是相同的。我们可以在 PyTorch 中通过将相同的权重矩阵分配给这些层来表示这一点
self.h_o.weight = self.i_h.weight应用RNNRegularizer 回调创建一个正则化的 Learner
learn = Learner(dls, LMModel7(len(vocab), 64, 2, 0.5),
loss_func=CrossEntropyLossFlat(), metrics=accuracy,
cbs=[ModelResetter, RNNRegularizer(alpha=2, beta=1)])TextLearner 自动为我们添加了这两个回调(使用 alpha 和 beta 的默认值)
learn = TextLearner(dls, LMModel7(len(vocab), 64, 2, 0.4),
loss_func=CrossEntropyLossFlat(), metrics=accuracy)这里我其实不太懂, 等要用的时候再看吧, 效果挺好, 正确率能到0.88

fastai13-Convolutions
学校里的课程就是学到卷积学不下去了...
卷积提取的是边缘特征, 关键是卷积核, 改变数值可以提取水平和竖直边缘
top_edge = tensor([[-1,-1,-1],
[ 0, 0, 0],
[ 1, 1, 1]]).float()PyTorch 可以同时对多张图像应用卷积
PyTorch 可以同时应用多个内核
PyTorch 最拿手的绝招是它能够利用 GPU 并行处理所有这些工作——即,对多个图像在多个通道上应用多个内核。并行处理大量工作对于使 GPU 高效工作至关重要;如果我们一次只执行这些操作中的一个,我们通常会慢几百倍(如果我们使用上一节中的手动卷积循环,我们会慢上百万倍!)。因此,要成为一名强大的深度学习实践者,练习的一项技能是一次给你的 GPU 分配大量的工作。
卷积的计算

这里有一个有趣的见解——卷积可以表示为一种特殊的矩阵乘法

步幅和填充
通过适当的填充,我们可以确保输出激活图与原始图像大小相同,这在构建我们的架构时可以大大简化。
如果我们添加一个大小为ks乘以ks的内核(其中ks是奇数),为了保持相同的形状,每侧所需的填充是ks//2。对于ks的偶数,顶部/底部和左侧/右侧需要不同的填充量,但在实践中我们几乎从不使用偶数滤波器大小。
步长为 2 的卷积对于减小我们的输出大小很有用,而步长为 1 的卷积对于在不改变输出大小的情况下增加层很有用。
创建一个卷积神经网络
broken_cnn = sequential(
# 输入图像的通道数, 输出图像的通道数
nn.Conv2d(1,30, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(30,1, kernel_size=3, padding=1)
)这样最终将得到28x28的激活图, 我们想要1x1的激活图, 通过调整步长实现
def conv(ni, nf, ks=3, act=True):
res = nn.Conv2d(ni, nf, stride=2, kernel_size=ks, padding=ks//2)
if act: res = nn.Sequential(res, nn.ReLU())
return ressimple_cnn = sequential(
conv(1 ,4), #14x14
conv(4 ,8), #7x7
conv(8 ,16), #4x4
conv(16,32), #2x2
conv(32,2, act=False), #1x1
Flatten(),
)当我们使用步长为 2 的卷积时,我们通常会增加特征的数量,因为我们正在将激活图中的激活数量减少 4 倍;我们不希望一次减少太多层的容量。
在网络的深层中,我们有语义丰富的特征,对应于更大的感受野(receptive field)。因此,我们预计我们需要为每个特征分配更多的权重来处理这种不断增加的复杂性。
彩色图像
只要在转换过程中不丢失信息,改变颜色的编码不会对你的模型结果产生任何影响。因此,转换为黑白图像是一个糟糕的主意,因为它完全去除了颜色信息(这可能是至关重要的;例如,宠物品种可能具有独特的颜色);但转换为 HSV 通常不会产生任何影响。
提高训练稳定性
这里有这样一个思想, 如果选用3*3的内核, 如果输出滤波器有8个, 这就说明在每个位置, 有8个值是从这9个像素计算出来的, 这实际上并没有学到很多
从一个操作的输入数量显著大于输出数量时,神经网络才会创建有用的特征。
增加批量大小
较大的批量具有更准确的梯度,因为它们是从更多的数据中计算出来的。然而,缺点是,较大的批量大小意味着每个 epoch 的批量更少,这意味着模型更新权重的次数更少。
1cycle 训练 | 1cycle Training
训练分为两个阶段, 一个阶段是学习率从最小值增长到最大值, 另一个阶段是学习率从最大值降低到最小值
这种训练方式基于这样的观察
- 一个泛化能力良好模型的损失不会因为输入的小量变化而产生很大的变化.
- 如果一个模型以较高的学习率训练了较长的时间, 并且还能找到一个很好的损失, 那么它一定找到了一个泛化能力良好的区域
- 直接跳到高学习率可能导致损失发散
- 一旦找到泛化能力良好的区域, 降低学习率找到该区域最好的部分
此外, 还引用了动量, 看图很好理解

多彩维度图 | color_dim

这个图没法复现, 也不太理解, 只知道末尾的一列是好的
这展示了一幅典型的“不良训练”画面。我们从几乎所有激活值都为零开始——这就是我们在最左边看到的,全是深蓝色。底部的亮黄色代表接近零的激活值。然后,在最初的几个批次中,我们看到非零激活值呈指数级增长,但是它走得太远了,崩溃了!我们看到深蓝色回归,底部再次变成亮黄色。它几乎看起来像是训练从头开始。然后我们看到激活值再次增加,再次崩溃。在重复几次之后,我们最终看到激活值在整个范围内分布。
批量归一化
批量归一化的模型泛化能力更好

def conv(ni, nf, ks=3, act=True):
layers = [nn.Conv2d(ni, nf, stride=2, kernel_size=ks, padding=ks//2)]
if act: layers.append(nn.ReLU())
layers.append(nn.BatchNorm2d(nf))
return nn.Sequential(*layers)fastai14-Resnet
卷积神经网络有这样两个问题
- 我们需要大量的步长为 2 的层来使我们的网格在最后变成 1×1
- 无法在除我们最初训练的尺寸之外的任何尺寸的图像上工作
全卷积网络 | fully convolutional networks
def avg_pool(x): return x.mean((2,3))前面正常卷积, 剩下的直接求平均
def block(ni, nf): return ConvLayer(ni, nf, stride=2)
def get_model():
return nn.Sequential(
block(3, 16),
block(16, 32),
block(32, 64),
block(64, 128),
block(128, 256),
nn.AdaptiveAvgPool2d(1),
Flatten(),
nn.Linear(256, dls.c))考虑这个问题:这种方法对于像 MNIST 这样的光学字符识别(OCR)问题有意义吗?大多数处理 OCR 和类似问题的从业者倾向于使用全卷积网络,因为这是现在几乎每个人都在学习的东西。但这真的没有任何意义!例如,你不能通过将数字切成小块,打乱它们,然后决定平均每个部分看起来像 3 还是 8 来决定一个数字是 3 还是 8。但这正是自适应平均池化实际上所做的!全卷积网络只有在没有单一正确方向或大小的物体上才是真正的好选择(例如,大多数自然照片)。
def get_learner(m):
return Learner(dls, m, loss_func=nn.CrossEntropyLoss(), metrics=accuracy
).to_fp16() # 切换到16为浮点数表示形式, 加快训练速度
跳跃连接 | Skip Connections
在 2015 年,ResNet 论文的作者注意到了一个他们觉得好奇的现象。即使在使用了批归一化之后,他们发现使用更多层的网络表现不如使用较少层的网络——而且这些模型之间没有其他差异。最有趣的是,这种差异不仅在验证集中观察到,也在训练集中观察到;因此,这不仅仅是泛化问题,而是训练问题。
起因是发现使用56层的网络不如使用20层的网络, 这不是由于过拟合引起的, 更高的层会导致更高的训练误差.
但是考虑在一个训练良好的20层的神经网络中添加额外的36层什么都不做的层, 它将做和20层一样的事情, 这就证明了存在和20层网络一样好的56层网络, 但是由于某种原因, SGD无法找到它.
这额外的36层ResNet是这样做的, 直接看代码就行
class ResBlock(Module):
def __init__(self, ni, nf):
self.convs = nn.Sequential(
ConvLayer(ni,nf),
ConvLayer(nf,nf, norm_type=NormType.BatchZero))
def forward(self, x): return x + self.convs(x)
# NormType.BatchZero 表示批量归一化层,其偏置和权重初始化为零。如果我们用x + conv(x)替换每个conv(x)的出现,其中conv是上一章中添加第二个卷积、然后是批量归一化层、然后是 ReLU 的函数。此外,回想一下批量归一化做了gamma*y + beta。如果我们为每个最终的批量归一化层初始化gamma为零会怎样?那么我们的conv(x)对于那些额外的 36 层将始终等于零,这意味着x+conv(x)将始终等于x。
如果给定层的输出是x, 当使用x+block(x)的ResNet块时, 我们并不是希望该块去预测y, 而是希望它去预测y与x之间的差异, 最终最小化x与y之间的误差, ResNet擅长学习"不做任何事情"和"通过两个卷积层"的微小差异.残差: 预测减去目标
在 ResNet 中,我们实际上并不是先训练较少数量的层,然后在末尾添加新的层并进行微调。相反,我们使用 ResNet 块,在整个 CNN 中从头开始初始化,并以通常的方式使用 SGD 进行训练。我们依赖跳跃连接使网络更容易使用 SGD 进行训练。
上面的代码块有两个问题, 步幅只能为1且要保证ni==nf, 我们对这个问题的解决方法是改变x的形状去匹配流过两层卷积的形状
def _conv_block(ni,nf,stride):
return nn.Sequential(
ConvLayer(ni, nf, stride=stride),
ConvLayer(nf, nf, act_cls=None, norm_type=NormType.BatchZero))class ResBlock(Module):
def __init__(self, ni, nf, stride=1):
self.convs = _conv_block(ni,nf,stride)
self.idconv = noop if ni==nf else ConvLayer(ni, nf, 1, act_cls=None)
self.pool = noop if stride==1 else nn.AvgPool2d(2, ceil_mode=True)
def forward(self, x):
return F.relu(self.convs(x) + self.idconv(self.pool(x)))解释: 如果ni!=nf, 那我们就让x通过1*1卷积, 如果步幅不为1, 我们就让x通过平均池化层
改进resnet
茎(stem): 神经网络的前几层, 通常茎的结构和神经网络主体结构不同
def _resnet_stem(*sizes):
return [
ConvLayer(sizes[i], sizes[i+1], 3, stride = 2 if i==0 else 1)
for i in range(len(sizes)-1)
] + [nn.MaxPool2d(kernel_size=3, stride=2, padding=1)]我们之所以采用简单的卷积层堆栈而不是 ResNet 模块,是基于对所有深度卷积神经网络的一个非常重要的洞察:绝大多数计算发生在早期层。因此,我们应该尽可能保持早期层的速度和简单性。
前几层包含大量的计算, 后几层包含大量的参数
ResNet-18
class ResNet(nn.Sequential):
def __init__(self, n_out, layers, expansion=1):
stem = _resnet_stem(3,32,32,64)
self.block_szs = [64, 64, 128, 256, 512]
for i in range(1,5): self.block_szs[i] *= expansion
blocks = [self._make_layer(*o) for o in enumerate(layers)]
super().__init__(*stem, *blocks,
nn.AdaptiveAvgPool2d(1), Flatten(),
nn.Linear(self.block_szs[-1], n_out))
def _make_layer(self, idx, n_layers):
stride = 1 if idx==0 else 2
ch_in,ch_out = self.block_szs[idx:idx+2]
return nn.Sequential(*[
ResBlock(ch_in if i==0 else ch_out, ch_out, stride if i==0 else 1)
for i in range(n_layers)
])
# ResNet-18
rn = ResNet(dls.c, [2,2,2,2])老实说我还不太熟悉
瓶颈层 | Bottleneck Layers
# 瓶颈层
def _conv_block(ni,nf,stride):
return nn.Sequential(
ConvLayer(ni, nf//4, 1),
ConvLayer(nf//4, nf//4, stride=stride),
ConvLayer(nf//4, nf, 1, act_cls=None, norm_type=NormType.BatchZero))回顾之前的卷积层
def _conv_block(ni,nf,stride):
return nn.Sequential(
ConvLayer(ni, nf, stride=stride),
ConvLayer(nf, nf, act_cls=None, norm_type=NormType.BatchZero))
这张图还是蛮形象的, 1x1的卷积核计算更快, 在更深层的网络中, 要使用更多的滤波器, 为了加快速的, 通过3x3卷积核之前减少通道数, 通过后恢复通道数
fastai15-arch details
计算机视觉
vision_learner用于分类任务, unet_learner用于图像生成任务, 自定义学习器的话我觉得直接看代码比较好
class SiameseImage(fastuple):
def show(self, ctx=None, **kwargs):
img1,img2,same_breed = self
if not isinstance(img1, Tensor):
if img2.size != img1.size: img2 = img2.resize(img1.size)
t1,t2 = tensor(img1),tensor(img2)
t1,t2 = t1.permute(2,0,1),t2.permute(2,0,1)
else: t1,t2 = img1,img2
line = t1.new_zeros(t1.shape[0], t1.shape[1], 10)
return show_image(torch.cat([t1,line,t2], dim=2),
title=same_breed, ctx=ctx)
def label_func(fname):
return re.match(r'^(.*)_\d+.jpg$', fname.name).groups()[0]
class SiameseTransform(Transform):
def __init__(self, files, label_func, splits):
self.labels = files.map(label_func).unique()
self.lbl2files = {l: L(f for f in files if label_func(f) == l) for l in self.labels}
self.label_func = label_func
self.valid = {f: self._draw(f) for f in files[splits[1]]}
def encodes(self, f):
f2,t = self.valid.get(f, self._draw(f))
img1,img2 = PILImage.create(f),PILImage.create(f2)
return SiameseImage(img1, img2, t)
def _draw(self, f):
same = random.random() < 0.5
cls = self.label_func(f)
if not same: cls = random.choice(L(l for l in self.labels if l != cls))
return random.choice(self.lbl2files[cls]),same
splits = RandomSplitter()(files)
tfm = SiameseTransform(files, label_func, splits)
tls = TfmdLists(files, tfm, splits=splits)
dls = tls.dataloaders(after_item=[Resize(224), ToTensor],
after_batch=[IntToFloatTensor, Normalize.from_stats(*imagenet_stats)])class SiameseModel(Module):
def __init__(self, encoder, head):
self.encoder,self.head = encoder,head
def forward(self, x1, x2):
ftrs = torch.cat([self.encoder(x1), self.encoder(x2)], dim=1)
return self.head(ftrs)encoder = create_body(resnet34(pretrained=True), cut=-2)head = create_head(512*2, 2, ps=0.5)model = SiameseModel(encoder, head)def loss_func(out, targ):
return nn.CrossEntropyLoss()(out, targ.long())def siamese_splitter(model):
return [params(model.encoder), params(model.head)]learn = Learner(dls, model, loss_func=loss_func,
splitter=siamese_splitter, metrics=accuracy)
learn.freeze()learn.fit_one_cycle(4, 3e-3)learn.unfreeze()
learn.fit_one_cycle(4, slice(1e-6,1e-4))后面我觉得晦涩难懂, 就不写了

fastai16-accel SGD
通用优化器
SGD | 随机梯度下降
def sgd_cb(p, lr, **kwargs): p.data.add_(-lr, p.grad.data)opt_func = partial(Optimizer, cbs=[sgd_cb])Momentum | 动量
def average_grad(p, mom, grad_avg=None, **kwargs):
if grad_avg is None: grad_avg = torch.zeros_like(p.grad.data)
return {'grad_avg': grad_avg*mom + p.grad.data}def momentum_step(p, lr, grad_avg, **kwargs): p.data.add_(-lr, grad_avg)opt_func = partial(Optimizer, cbs=[average_grad,momentum_step], mom=0.9)RMSProp
def average_sqr_grad(p, sqr_mom, sqr_avg=None, **kwargs):
if sqr_avg is None: sqr_avg = torch.zeros_like(p.grad.data)
return {'sqr_avg': sqr_mom*sqr_avg + (1-sqr_mom)*p.grad.data**2}
def rms_prop_step(p, lr, sqr_avg, eps, grad_avg=None, **kwargs):
denom = sqr_avg.sqrt().add_(eps)
p.data.addcdiv_(-lr, p.grad, denom) #p.data = p.data - lr * p.grad / denomopt_func = partial(Optimizer, cbs=[average_sqr_grad,rms_prop_step],
sqr_mom=0.99, eps=1e-7)Adam
# 一阶矩估计
def average_grad(p, mom, grad_avg=None, **kwargs):
if grad_avg is None:
grad_avg = torch.zeros_like(p.grad.data)
return {'grad_avg': grad_avg*mom + (1-mom)*p.grad.data}
# 二阶矩估计
def average_sqr_grad(p, sqr_mom, sqr_avg=None, **kwargs):
if sqr_avg is None:
sqr_avg = torch.zeros_like(p.grad.data)
return {'sqr_avg': sqr_mom*sqr_avg + (1-sqr_mom)*p.grad.data**2}
# Adam 更新步骤
def adam_step(p, lr, grad_avg, sqr_avg, eps, step, mom, sqr_mom, **kwargs):
# 对一阶矩和二阶矩进行偏差校正
corrected_grad_avg = grad_avg / (1 - mom**step)
corrected_sqr_avg = sqr_avg / (1 - sqr_mom**step)
denom = corrected_sqr_avg.sqrt().add_(eps)
p.data.addcdiv_(-lr, corrected_grad_avg, denom)
step +=1
# 定义优化器
opt_func = partial(Optimizer, cbs=[average_grad, average_sqr_grad, adam_step], mom=0.9, sqr_mom=0.99, eps=1e-8, step=1)
回调 | callbacks
这里的介绍更像文档
可以使用回调的阶段
| 事件 | 描述 |
|---|---|
| before_fit | 在执行任何操作之前调用;理想用于初始设置。 |
| before_epoch | 在每个epoch开始时调用;对需要在每个epoch重置的行为很有用。 |
| before_train | 在一个epoch的训练部分开始时调用。 |
| before_batch | 在每个批次开始时调用,刚在提取该批次后。可用于为批次做必要的设置(如超参数调度)或在输入/目标进入模型之前进行更改(例如应用Mixup)。 |
| after_pred | 在计算完批次的模型输出后调用。可用于在输出传递到损失函数之前更改该输出。 |
| after_loss | 在损失计算完毕但在反向传播之前调用。可用于在损失中添加惩罚(例如在RNN训练中的AR或TAR)。 |
| after_backward | 在反向传播后,但在参数更新之前调用。可用于在参数更新前对梯度进行更改(例如通过梯度裁剪)。 |
| after_step | 在步骤之后和梯度归零之前调用。 |
| after_batch | 在一个批次结束时调用,以在下一个批次之前执行任何所需的清理工作。 |
| after_train | 在一个epoch的训练阶段结束时调用。 |
| before_validate | 在一个epoch的验证阶段开始时调用;对验证特定的设置很有用。 |
| after_validate | 在一个epoch的验证部分结束时调用。 |
| after_epoch | 在一个epoch结束时调用,以在下一个epoch之前进行任何清理工作。 |
| after_fit | 在训练结束时调用,用于最终清理工作。 |
class ModelResetter(Callback):
def before_train(self): self.model.reset()
def before_validate(self): self.model.reset()训练和验证开始时调用reset
class RNNRegularizer(Callback):
def __init__(self, alpha=0., beta=0.): self.alpha,self.beta = alpha,beta
def after_pred(self):
self.raw_out,self.out = self.pred[1],self.pred[2]
self.learn.pred = self.pred[0]
def after_loss(self):
if not self.training: return
if self.alpha != 0.:
self.learn.loss += self.alpha * self.out[-1].float().pow(2).mean()
if self.beta != 0.:
h = self.raw_out[-1]
if len(h)>1:
self.learn.loss += self.beta * (h[:,1:] - h[:,:-1]
).float().pow(2).mean()RNN正则化
可以使用的参数
| 属性 | 描述 |
|---|---|
| model | 用于训练/验证的模型。 |
| data | 底层的数据加载器(DataLoaders)。 |
| loss_func | 使用的损失函数。 |
| opt | 用于更新模型参数的优化器。 |
| opt_func | 用于创建优化器的函数。 |
| cbs | 包含所有回调函数的列表。 |
| dl | 当前用于迭代的数据加载器(DataLoader)。 |
| x/xb | 从self.dl提取的最后一个输入(可能已被回调函数修改)。xb始终是一个元组(可能只有一个元素),x是去元组化的。你只能赋值给xb。 |
| y/yb | 从self.dl提取的最后一个目标(可能已被回调函数修改)。yb始终是一个元组(可能只有一个元素),y是去元组化的。你只能赋值给yb。 |
| pred | 来自self.model的最后一次预测(可能已被回调函数修改)。 |
| loss | 最后计算的损失(可能已被回调函数修改)。 |
| n_epoch | 本次训练的总epoch数。 |
| n_iter | 当前self.dl中的迭代次数。 |
| epoch | 当前的epoch索引(从0到n_epoch-1)。 |
| iter | self.dl中的当前迭代索引(从0到n_iter-1)。 |
以下属性由TrainEvalCallback添加,除非你特意移除了该回调,否则应该可用:
| 属性 | 描述 |
|---|---|
| train_iter | 自训练开始以来完成的训练迭代次数。 |
| pct_train | 完成的训练迭代的百分比(从0到1)。 |
| training | 一个标志,指示我们是否处于训练模式。 |
以下属性由Recorder添加,除非你特意移除了该回调,否则应该可用:
| 属性 | 描述 |
|---|---|
| smooth_loss | 训练损失的指数平均版本。 |
回调还可以使用异常系统中断训练循环的任何部分。
fastai17-Foundations
矩阵乘法
def matmul(a,b):
ar,ac = a.shape # n_rows * n_cols
br,bc = b.shape
assert ac==br
c = torch.zeros(ar, bc)
for i in range(ar):
for j in range(bc):
for k in range(ac): c[i,j] += a[i,k] * b[k,j]
return c
使用torch内置@计算

逐元素算术运算
def matmul(a,b):
ar,ac = a.shape
br,bc = b.shape
assert ac==br
c = torch.zeros(ar, bc)
for i in range(ar):
for j in range(bc): c[i,j] = (a[i] * b[:,j]).sum()
return c
广播
c = tensor([10.,20,30])
m = tensor([[1., 2, 3], [4,5,6], [7,8,9]])
c.shape, m.shape(torch.Size([3]), torch.Size([3, 3]))
t = c.expand_as(m)
ttensor([[10., 20., 30.], [10., 20., 30.], [10., 20., 30.]])
尽管张量正式包含九个元素, 但内存中仅存储了三个标量. 这一巧妙之处在于为该维度赋予了 0 的步长
t.storage(), t.stride()( 10.0 20.0 30.0 [torch.storage.TypedStorage(dtype=torch.float32, device=cpu) of size 3], (0, 1))
广播过程中, 默认情况下, 如果我们需要增加维度, 它们会被添加在开头
c = tensor([10.,20,30])
c.shape, c.unsqueeze(0).shape,c.unsqueeze(1).shape(torch.Size([3]), torch.Size([1, 3]), torch.Size([3, 1]))
unsqueeze可以用None替换
c.shape, c[None,:].shape,c[:,None].shape(torch.Size([3]), torch.Size([1, 3]), torch.Size([3, 1]))
c[None].shape,c[...,None].shape(torch.Size([1, 3]), torch.Size([3, 1]))
def matmul(a,b):
ar,ac = a.shape
br,bc = b.shape
assert ac==br
c = torch.zeros(ar, bc)
for i in range(ar):
# c[i,j] = (a[i,:] * b[:,j]).sum() # previous
c[i] = (a[i].unsqueeze(-1) * b).sum(dim=0)
return c
在处理两个张量时,PyTorch 会逐元素比较它们的形状。它从尾部维度开始,逐步向前推进,遇到空维度时添加 1。当满足以下任一条件时,两个维度被认为是兼容的:
1. 它们是平等的。
2. 其中之一为1时,该维度会进行广播以匹配另一维度的大小。
爱因斯坦求和
首先看一个最简单的矩阵乘法
torch.einsum('ik,kj->ij', a, b)out[i, j] = sum_k a[i, k] * b[k, j]
# or 伪代码
# for m in range(k):
# out[i, j] += a[i, m] * b[m, j]转置
torch.einsum('ij->ji', a)out[j, i] = a[i, j]多元
torch.einsum('bi,ij,bj->b', a, b, c)out[b] = sum_i sum_j a[b, i] * b[i, j] * c[b, j]
#for m in range(i):
# for n in range(j):
# out[b] += a[b, i]*b[i, j]*c[b, j]多维
torch.einsum('bik,bkj->bij', a, b)sum[b, i, j] = sum_k a[b, i, k]*b[b, k, j]
#for m i range(k):
# out[b, i, j] += a[b, i, m]*b[b, m, j]现在再看'爱因斯坦求和约定规则'就很清楚了
- 左侧的重复指标若未出现在右侧,则默认为求和指标。
- 每个索引在左侧最多出现两次。
- 左侧未重复的指标必须在右侧出现。
权重初始化
# 定义和初始化层
def lin(x, w, b): return x @ w + b
# 输入输出
x = torch.randn(200, 100)
y = torch.randn(200)
# Xavier 初始化(或 Glorot 初始化)
from math import sqrt
w1 = torch.randn(100,50) / sqrt(100)
b1 = torch.zeros(50)
w2 = torch.randn(50,1) / sqrt(50)
b2 = torch.zeros(1)关于这样初始化的理由, 看一张图就明白了

接下来加了relu层又会爆炸

新的初始化方法

因为这个概念我在其他教程中学过故跳过
前向传播的完整代码
# 前向传播
x = torch.randn(200, 100)
y = torch.randn(200)
w1 = torch.randn(100,50) * sqrt(2 / 100)
b1 = torch.zeros(50)
w2 = torch.randn(50,1) * sqrt(2 / 50)
b2 = torch.zeros(1)
# 定义和初始化层
def lin(x, w, b): return x @ w + b
def model(x):
l1 = lin(x, w1, b1)
l2 = relu(l1)
l3 = lin(l2, w2, b2)
return l3
out = model(x)
out.mean(), out.std(), out.shape
# (tensor(0.5747), tensor(1.3031), torch.Size([200, 1]))计算损失
def mse(output, targ): return (output.squeeze(-1) - targ).pow(2).mean()
loss = mse(out, y)
losstensor(2.9242)
反向传播还是得看Andrej Karpathy
$$\frac{\text{d} loss}{\text{d} b_{2}} = \frac{\text{d} loss}{\text{d} out} \times \frac{\text{d} out}{\text{d} b_{2}} = \frac{\text{d}}{\text{d} out} mse(out, y) \times \frac{\text{d}}{\text{d} b_{2}} lin(l_{2}, w_{2}, b_{2})$$
def mse_grad(inp, targ):
# grad of loss with respect to output of previous layer
inp.g = 2. * (inp.squeeze() - targ).unsqueeze(-1) / inp.shape[0]def relu_grad(inp, out):
# grad of relu with respect to input activations
inp.g = (inp>0).float() * out.gdef lin_grad(inp, out, w, b):
# grad of matmul with respect to input
inp.g = out.g @ w.t()
w.g = inp.t() @ out.g
b.g = out.g.sum(0)计算梯度,PyTorch 帮我们完成,展示方程,SymPy 为我们代劳!

重构代码
class Relu():
def __call__(self, inp):
self.inp = inp
self.out = inp.clamp_min(0.)
return self.out
def backward(self): self.inp.g = (self.inp>0).float() * self.out.g
class Lin():
def __init__(self, w, b): self.w,self.b = w,b
def __call__(self, inp):
self.inp = inp
self.out = inp@self.w + self.b
return self.out
def backward(self):
self.inp.g = self.out.g @ self.w.t()
self.w.g = self.inp.t() @ self.out.g
self.b.g = self.out.g.sum(0)
class Mse():
def __call__(self, inp, targ):
self.inp = inp
self.targ = targ
self.out = (inp.squeeze() - targ).pow(2).mean()
return self.out
def backward(self):
x = (self.inp.squeeze()-self.targ).unsqueeze(-1)
self.inp.g = 2.*x/self.targ.shape[0]
class Model():
def __init__(self, w1, b1, w2, b2):
self.layers = [Lin(w1,b1), Relu(), Lin(w2,b2)]
self.loss = Mse()
def __call__(self, x, targ):
for l in self.layers: x = l(x)
return self.loss(x, targ)
def backward(self):
self.loss.backward()
for l in reversed(self.layers): l.backward()
model = Model(w1, b1, w2, b2)
loss = model(x, y)
model.backward()继续重构
class LayerFunction():
def __call__(self, *args):
self.args = args
self.out = self.forward(*args)
return self.out
def forward(self): raise Exception('not implemented')
def bwd(self): raise Exception('not implemented')
def backward(self): self.bwd(self.out, *self.args)
class Relu(LayerFunction):
def forward(self, inp): return inp.clamp_min(0.)
def bwd(self, out, inp): inp.g = (inp>0).float() * out.g
class Lin(LayerFunction):
def __init__(self, w, b): self.w,self.b = w,b
def forward(self, inp): return inp@self.w + self.b
def bwd(self, out, inp):
inp.g = out.g @ self.w.t()
self.w.g = inp.t() @ self.out.g
self.b.g = out.g.sum(0)
class Mse(LayerFunction):
def forward (self, inp, targ): return (inp.squeeze() - targ).pow(2).mean()
def bwd(self, out, inp, targ):
inp.g = 2*(inp.squeeze()-targ).unsqueeze(-1) / targ.shape[0]转向pytorch
实际自己自定义类的情况非常少, 下面给个实例, 估计我也用不到
from torch.autograd import Function
class MyRelu(Function):
@staticmethod
def forward(ctx, i):
result = i.clamp_min(0.)
ctx.save_for_backward(i)
return result
@staticmethod
def backward(ctx, grad_output):
i, = ctx.saved_tensors
return grad_output * (i>0).float()从0开始的线性层
import torch.nn as nn
class LinearLayer(nn.Module):
def __init__(self, n_in, n_out):
super().__init__()
self.weight = nn.Parameter(torch.randn(n_in, n_out) * sqrt(2/n_in))
self.bias = nn.Parameter(torch.zeros(n_out))
def forward(self, x): return x @ self.weight.t() + self.biasfastai的变体
class Model(Module):
def __init__(self, n_in, nh, n_out):
self.layers = nn.Sequential(
nn.Linear(n_in,nh), nn.ReLU(), nn.Linear(nh,n_out))
self.loss = mse
def forward(self, x, targ): return self.loss(self.layers(x).squeeze(), targ)
fastai18-ACM
CAM and Hooks
The class activation map (CAM) 翻译为类激活图
它可以做的事情用一张图概括

亮黄色区域代表高激活区, 而紫色区域则代表低激活区. 在这种情况下, 我们可以看到头部和前爪是促使模型判定图片为猫的两个主要区域. 它为我们揭示了卷积神经网络做出特定预测的原因.
数据准备
# 训练好的模型
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=21,
label_func=is_cat, item_tfms=Resize(224))
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
# 读取图片
img = PILImage.create(image_cat())
# 预处理图片
x, = first(dls.test_dl([img]))定义钩子
class Hook():
def __init__(self, m):
self.hook = m.register_forward_hook(self.hook_func)
def hook_func(self, m, i, o): self.stored = o.detach().clone()
def __enter__(self, *args): return self
def __exit__(self, *args): self.hook.remove()
with Hook(learn.model[0]) as hook:
with torch.no_grad(): output = learn.model.eval()(x.cuda())
act = hook.stored可视化
cam_map = torch.einsum('ck,kij->cij', learn.model[1][-1].weight, act)
cam_map.shape
x_dec = TensorImage(dls.train.decode((x,))[0][0])
_,ax = plt.subplots()
x_dec.show(ctx=ax)
ax.imshow(cam_map[1].detach().cpu(), alpha=0.6, extent=(0,224,224,0),
interpolation='bilinear', cmap='magma');
cls = 1
with HookBwd(learn.model[0]) as hookg:
with Hook(learn.model[0]) as hook:
output = learn.model.eval()(x.cpu())
act = hook.stored
output[0,cls].backward()
grad = hookg.storedGradient_CAM
我们刚才看到的方法仅允许我们使用最后的激活来计算热图,因为一旦我们获得了特征,就必须将它们乘以最后一个权重矩阵。这对于网络内部的层并不适用。
为此我们定义了HookBwd
# Gradient_CAM
class HookBwd():
def __init__(self, m):
self.hook = m.register_backward_hook(self.hook_func)
def hook_func(self, m, gi, go): self.stored = go[0].detach().clone()
def __enter__(self, *args): return self
def __exit__(self, *args): self.hook.remove()
cls = 1
with HookBwd(learn.model[0]) as hookg:
with Hook(learn.model[0]) as hook:
output = learn.model.eval()(x.cuda())
act = hook.stored
output[0,cls].backward()
grad = hookg.stored可视化
w = grad[0].mean(dim=[1,2], keepdim=True)
cam_map = (w * act[0]).sum(0)
_,ax = plt.subplots()
x_dec.show(ctx=ax)
ax.imshow(cam_map.detach().cpu(), alpha=0.6, extent=(0,224,224,0),
interpolation='bilinear', cmap='magma');这里learn.model[1][-1].weight, act, cam_map之类的含义我并不清楚, 原因在于实践太少了, 因此不愿在此花时间去理解, 理解概念就行.
模型解释是当前活跃的研究领域,本章仅浅尝辄止地探讨了其可能性。类激活映射通过展示图像中对特定预测影响最大的区域,帮助我们洞察模型为何做出特定预测。这有助于我们分析误报情况,并找出训练数据中缺失的部分,以避免类似错误。
